
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!
# 98. 所有可达路径
卡码网题目链接(ACM模式) (opens new window)
【题目描述】
给定一个有 n 个节点的有向无环图,节点编号从 1 到 n。请编写一个程序,找出并返回所有从节点 1 到节点 n 的路径。每条路径应以节点编号的列表形式表示。
【输入描述】
第一行包含两个整数 N,M,表示图中拥有 N 个节点,M 条边
后续 M 行,每行包含两个整数 s 和 t,表示图中的 s 节点与 t 节点中有一条路径
【输出描述】
输出所有的可达路径,路径中所有节点的后面跟一个空格,每条路径独占一行,存在多条路径,路径输出的顺序可任意。
如果不存在任何一条路径,则输出 -1。
注意输出的序列中,最后一个节点后面没有空格! 例如正确的答案是 1 3 5,而不是 1 3 5, 5后面没有空格!
【输入示例】
5 5
1 3
3 5
1 2
2 4
4 5
2
3
4
5
6
【输出示例】
1 3 5
1 2 4 5
2
提示信息
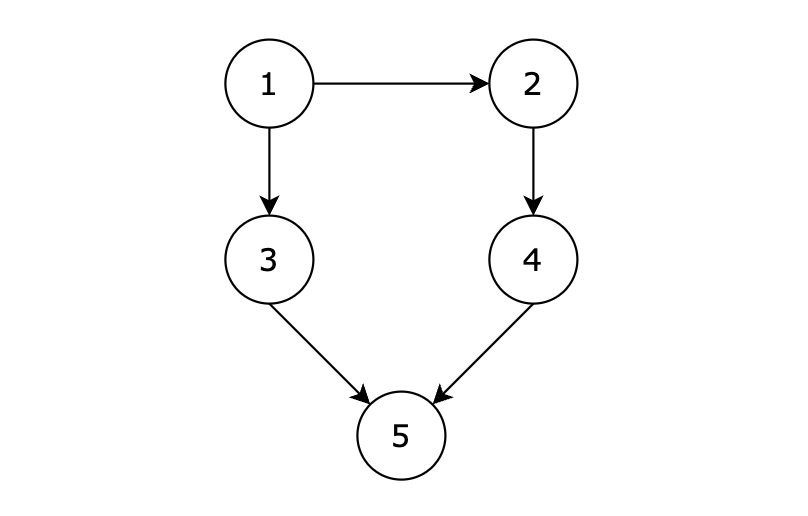
用例解释:
有五个节点,其中的从 1 到达 5 的路径有两个,分别是 1 -> 3 -> 5 和 1 -> 2 -> 4 -> 5。
因为拥有多条路径,所以输出结果为:
1 3 5
1 2 4 5
2
或
1 2 4 5
1 3 5
2
都算正确。
数据范围:
- 图中不存在自环
- 图中不存在平行边
- 1 <= N <= 100
- 1 <= M <= 500
《代码随想录》算法视频公开课 (opens new window):所有可达路径 (opens new window),相信结合视频再看本篇题解,更有助于大家对本题的理解。
# 插曲
本题和力扣 797.所有可能的路径 (opens new window) 是一样的,录友了解深度优先搜索之后,这道题目就是模板题,是送分题。
力扣是核心代码模式,把图的存储方式给大家定义好了,只需要写出深搜的核心代码就可以。
如果笔试的时候出一道原题 (笔试都是ACM模式,部分面试也是ACM模式),不少熟练刷力扣的录友都难住了,因为不知道图应该怎么存,也不知道自己存的图如何去遍历。
所以这也是为什么我要让大家练习 ACM模式,也是我为什么 在代码随想录图论讲解中,不惜自己亲自出题,让大家统一练习ACM模式。
这道题目是深度优先搜索,比较好的入门题。
如果对深度优先搜索还不够了解,可以先看这里:深度优先搜索的理论基础 (opens new window)
我依然总结了深搜三部曲,如果按照代码随想录刷题的录友,应该刷过 二叉树的递归三部曲,回溯三部曲。
大家可能有疑惑,深搜 和 二叉树和回溯算法 有什么区别呢? 什么时候用深搜 什么时候用回溯?
我在讲解二叉树理论基础 (opens new window)的时候,提到过,二叉树的前中后序遍历其实就是深搜在二叉树这种数据结构上的应用。
那么回溯算法呢,其实 回溯算法就是 深搜,只不过针对某一搜索场景 我们给他一个更细分的定义,叫做回溯算法。
那有的录友可能说:那我以后称回溯算法为深搜,是不是没毛病?
理论上来说,没毛病,但 就像是 二叉树 你不叫它二叉树,叫它数据结构,有问题不? 也没问题对吧。
建议是 有细分的场景,还是称其细分场景的名称。 所以回溯算法可以独立出来,但回溯确实就是深搜。
# 图的存储
在图论理论基础篇 中我们讲到了 两种 图的存储方式:邻接表 和 邻接矩阵。
本题我们将带大家分别实现这两个图的存储方式。
# 邻接矩阵
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
本题我们会有n 个节点,因为节点标号是从1开始的,为了节点标号和下标对齐,我们申请 n + 1 * n + 1 这么大的二维数组。
vector<vector<int>> graph(n + 1, vector<int>(n + 1, 0));
输入m个边,构造方式如下:
while (m--) {
cin >> s >> t;
// 使用邻接矩阵 ,1 表示 节点s 指向 节点t
graph[s][t] = 1;
}
2
3
4
5
# 邻接表
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
邻接表的构造相对邻接矩阵难理解一些。
我在 图论理论基础篇 举了一个例子:

这里表达的图是:
- 节点1 指向 节点3 和 节点5
- 节点2 指向 节点4、节点3、节点5
- 节点3 指向 节点4
- 节点4指向节点1
我们需要构造一个数组,数组里的元素是一个链表。
C++写法:
// 节点编号从1到n,所以申请 n+1 这么大的数组
vector<list<int>> graph(n + 1); // 邻接表,list为C++里的链表
2
输入m个边,构造方式如下:
while (m--) {
cin >> s >> t;
// 使用邻接表 ,表示 s -> t 是相连的
graph[s].push_back(t);
}
2
3
4
5
本题我们使用邻接表 或者 邻接矩阵都可以,因为后台数据并没有对图的大小以及稠密度做很大的区分。
以下我们使用邻接矩阵的方式来讲解,文末我也会给出 使用邻接表的整体代码。
注意邻接表 和 邻接矩阵的写法都要掌握!
# 深度优先搜索
本题是深度优先搜索的基础题目,关于深搜我在图论深搜理论基础 已经有详细的讲解,图文并茂。
关于本题我会直接使用深搜三部曲来分析,如果对深搜不够了解,建议先看 图论深搜理论基础。
深搜三部曲来分析题目:
- 确认递归函数,参数
首先我们dfs函数一定要存一个图,用来遍历的,需要存一个目前我们遍历的节点,定义为x。
还需要存一个n,表示终点,我们遍历的时候,用来判断当 x==n 时候 标明找到了终点。
(其实在递归函数的参数 不容易一开始就确定了,一般是在写函数体的时候发现缺什么,参加就补什么)
至于 单一路径 和 路径集合 可以放在全局变量,那么代码是这样的:
vector<vector<int>> result; // 收集符合条件的路径
vector<int> path; // 0节点到终点的路径
// x:目前遍历的节点
// graph:存当前的图
// n:终点
void dfs (const vector<vector<int>>& graph, int x, int n) {
2
3
4
5
6
- 确认终止条件
什么时候我们就找到一条路径了?
当目前遍历的节点 为 最后一个节点 n 的时候 就找到了一条 从出发点到终止点的路径。
// 当前遍历的节点x 到达节点n
if (x == n) { // 找到符合条件的一条路径
result.push_back(path);
return;
}
2
3
4
5
- 处理目前搜索节点出发的路径
接下来是走 当前遍历节点x的下一个节点。
首先是要找到 x节点指向了哪些节点呢? 遍历方式是这样的:
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
if (graph[x][i] == 1) { // 找到 x指向的节点,就是节点i
}
}
2
3
4
接下来就是将 选中的x所指向的节点,加入到 单一路径来。
path.push_back(i); // 遍历到的节点加入到路径中来
2
进入下一层递归
dfs(graph, i, n); // 进入下一层递归
最后就是回溯的过程,撤销本次添加节点的操作。
为什么要有回溯,我在图论深搜理论基础 也有详细的讲解。
该过程整体代码:
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
if (graph[x][i] == 1) { // 找到 x链接的节点
path.push_back(i); // 遍历到的节点加入到路径中来
dfs(graph, i, n); // 进入下一层递归
path.pop_back(); // 回溯,撤销本节点
}
}
2
3
4
5
6
7
# 打印结果
ACM格式大家在输出结果的时候,要关注看看格式问题,特别是字符串,有的题目说的是每个元素后面都有空格,有的题目说的是 每个元素间有空格,最后一个元素没有空格。
有的题目呢,压根没说,那只能提交去试一试了。
很多录友在提交题目的时候发现结果一样,为什么提交就是不对呢。
例如示例输出是:
1 3 5 而不是 1 3 5
即 5 的后面没有空格!
这是我们在输出的时候需要注意的点。
有录友可能会想,ACM格式就是麻烦,有空格没有空格有什么影响,结果对了不就行了?
ACM模式相对于核心代码模式(力扣) 更考验大家对代码的掌控能力。 例如工程代码里,输入输出都是要自己控制的。这也是为什么大公司笔试,都是ACM模式。
以上代码中,结果都存在了 result数组里(二维数组,每一行是一个结果),最后将其打印出来。(重点看注释)
// 输出结果
if (result.size() == 0) cout << -1 << endl;
for (const vector<int> &pa : result) {
for (int i = 0; i < pa.size() - 1; i++) { // 这里指打印到倒数第二个
cout << pa[i] << " ";
}
cout << pa[pa.size() - 1] << endl; // 这里再打印倒数第一个,控制最后一个元素后面没有空格
}
2
3
4
5
6
7
8
# 本题代码
# 邻接矩阵写法
#include <iostream>
#include <vector>
using namespace std;
vector<vector<int>> result; // 收集符合条件的路径
vector<int> path; // 1节点到终点的路径
void dfs (const vector<vector<int>>& graph, int x, int n) {
// 当前遍历的节点x 到达节点n
if (x == n) { // 找到符合条件的一条路径
result.push_back(path);
return;
}
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
if (graph[x][i] == 1) { // 找到 x链接的节点
path.push_back(i); // 遍历到的节点加入到路径中来
dfs(graph, i, n); // 进入下一层递归
path.pop_back(); // 回溯,撤销本节点
}
}
}
int main() {
int n, m, s, t;
cin >> n >> m;
// 节点编号从1到n,所以申请 n+1 这么大的数组
vector<vector<int>> graph(n + 1, vector<int>(n + 1, 0));
while (m--) {
cin >> s >> t;
// 使用邻接矩阵 表示无线图,1 表示 s 与 t 是相连的
graph[s][t] = 1;
}
path.push_back(1); // 无论什么路径已经是从0节点出发
dfs(graph, 1, n); // 开始遍历
// 输出结果
if (result.size() == 0) cout << -1 << endl;
for (const vector<int> &pa : result) {
for (int i = 0; i < pa.size() - 1; i++) {
cout << pa[i] << " ";
}
cout << pa[pa.size() - 1] << endl;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 邻接表写法
#include <iostream>
#include <vector>
#include <list>
using namespace std;
vector<vector<int>> result; // 收集符合条件的路径
vector<int> path; // 1节点到终点的路径
void dfs (const vector<list<int>>& graph, int x, int n) {
if (x == n) { // 找到符合条件的一条路径
result.push_back(path);
return;
}
for (int i : graph[x]) { // 找到 x指向的节点
path.push_back(i); // 遍历到的节点加入到路径中来
dfs(graph, i, n); // 进入下一层递归
path.pop_back(); // 回溯,撤销本节点
}
}
int main() {
int n, m, s, t;
cin >> n >> m;
// 节点编号从1到n,所以申请 n+1 这么大的数组
vector<list<int>> graph(n + 1); // 邻接表
while (m--) {
cin >> s >> t;
// 使用邻接表 ,表示 s -> t 是相连的
graph[s].push_back(t);
}
path.push_back(1); // 无论什么路径已经是从0节点出发
dfs(graph, 1, n); // 开始遍历
// 输出结果
if (result.size() == 0) cout << -1 << endl;
for (const vector<int> &pa : result) {
for (int i = 0; i < pa.size() - 1; i++) {
cout << pa[i] << " ";
}
cout << pa[pa.size() - 1] << endl;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 总结
本题是一道简单的深搜题目,也可以说是模板题,和 力扣797. 所有可能的路径 (opens new window) 思路是一样一样的。
很多录友做力扣的时候,轻松就把代码写出来了, 但做面试笔试的时候,遇到这样的题就写不出来了。
在力扣上刷题不用考虑图的存储方式,也不用考虑输出的格式。
而这些都是 ACM 模式题目的知识点(图的存储方式)和细节(输出的格式)
所以我才会特别制作ACM题目,同样也重点去讲解图的存储和遍历方式,来帮大家去练习。
对于这种有向图路径问题,最合适使用深搜,当然本题也可以使用广搜,但广搜相对来说就麻烦了一些,需要记录一下路径。
而深搜和广搜都适合解决颜色类的问题,例如岛屿系列,其实都是 遍历+标记,所以使用哪种遍历都是可以的。
至于广搜理论基础,我们在下一篇在好好讲解,敬请期待!
# 其他语言版本
# Java
邻接矩阵写法
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main {
static List<List<Integer>> result = new ArrayList<>(); // 收集符合条件的路径
static List<Integer> path = new ArrayList<>(); // 1节点到终点的路径
public static void dfs(int[][] graph, int x, int n) {
// 当前遍历的节点x 到达节点n
if (x == n) { // 找到符合条件的一条路径
result.add(new ArrayList<>(path));
return;
}
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
if (graph[x][i] == 1) { // 找到 x链接的节点
path.add(i); // 遍历到的节点加入到路径中来
dfs(graph, i, n); // 进入下一层递归
path.remove(path.size() - 1); // 回溯,撤销本节点
}
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
// 节点编号从1到n,所以申请 n+1 这么大的数组
int[][] graph = new int[n + 1][n + 1];
for (int i = 0; i < m; i++) {
int s = scanner.nextInt();
int t = scanner.nextInt();
// 使用邻接矩阵表示无向图,1 表示 s 与 t 是相连的
graph[s][t] = 1;
}
path.add(1); // 无论什么路径已经是从1节点出发
dfs(graph, 1, n); // 开始遍历
// 输出结果
if (result.isEmpty()) System.out.println(-1);
for (List<Integer> pa : result) {
for (int i = 0; i < pa.size() - 1; i++) {
System.out.print(pa.get(i) + " ");
}
System.out.println(pa.get(pa.size() - 1));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
邻接表写法
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Scanner;
public class Main {
static List<List<Integer>> result = new ArrayList<>(); // 收集符合条件的路径
static List<Integer> path = new ArrayList<>(); // 1节点到终点的路径
public static void dfs(List<LinkedList<Integer>> graph, int x, int n) {
if (x == n) { // 找到符合条件的一条路径
result.add(new ArrayList<>(path));
return;
}
for (int i : graph.get(x)) { // 找到 x指向的节点
path.add(i); // 遍历到的节点加入到路径中来
dfs(graph, i, n); // 进入下一层递归
path.remove(path.size() - 1); // 回溯,撤销本节点
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
// 节点编号从1到n,所以申请 n+1 这么大的数组
List<LinkedList<Integer>> graph = new ArrayList<>(n + 1);
for (int i = 0; i <= n; i++) {
graph.add(new LinkedList<>());
}
while (m-- > 0) {
int s = scanner.nextInt();
int t = scanner.nextInt();
// 使用邻接表表示 s -> t 是相连的
graph.get(s).add(t);
}
path.add(1); // 无论什么路径已经是从1节点出发
dfs(graph, 1, n); // 开始遍历
// 输出结果
if (result.isEmpty()) System.out.println(-1);
for (List<Integer> pa : result) {
for (int i = 0; i < pa.size() - 1; i++) {
System.out.print(pa.get(i) + " ");
}
System.out.println(pa.get(pa.size() - 1));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# Python
邻接矩阵写法
def dfs(graph, x, n, path, result):
if x == n:
result.append(path.copy())
return
for i in range(1, n + 1):
if graph[x][i] == 1:
path.append(i)
dfs(graph, i, n, path, result)
path.pop()
def main():
n, m = map(int, input().split())
graph = [[0] * (n + 1) for _ in range(n + 1)]
for _ in range(m):
s, t = map(int, input().split())
graph[s][t] = 1
result = []
dfs(graph, 1, n, [1], result)
if not result:
print(-1)
else:
for path in result:
print(' '.join(map(str, path)))
if __name__ == "__main__":
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
邻接表写法
from collections import defaultdict
result = [] # 收集符合条件的路径
path = [] # 1节点到终点的路径
def dfs(graph, x, n):
if x == n: # 找到符合条件的一条路径
result.append(path.copy())
return
for i in graph[x]: # 找到 x指向的节点
path.append(i) # 遍历到的节点加入到路径中来
dfs(graph, i, n) # 进入下一层递归
path.pop() # 回溯,撤销本节点
def main():
n, m = map(int, input().split())
graph = defaultdict(list) # 邻接表
for _ in range(m):
s, t = map(int, input().split())
graph[s].append(t)
path.append(1) # 无论什么路径已经是从1节点出发
dfs(graph, 1, n) # 开始遍历
# 输出结果
if not result:
print(-1)
for pa in result:
print(' '.join(map(str, pa)))
if __name__ == "__main__":
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Go
# 邻接矩阵写法
package main
import (
"fmt"
)
var result [][]int // 收集符合条件的路径
var path []int // 1节点到终点的路径
func dfs(graph [][]int, x, n int) {
// 当前遍历的节点x 到达节点n
if x == n { // 找到符合条件的一条路径
temp := make([]int, len(path))
copy(temp, path)
result = append(result, temp)
return
}
for i := 1; i <= n; i++ { // 遍历节点x链接的所有节点
if graph[x][i] == 1 { // 找到 x链接的节点
path = append(path, i) // 遍历到的节点加入到路径中来
dfs(graph, i, n) // 进入下一层递归
path = path[:len(path)-1] // 回溯,撤销本节点
}
}
}
func main() {
var n, m int
fmt.Scanf("%d %d", &n, &m)
// 节点编号从1到n,所以申请 n+1 这么大的数组
graph := make([][]int, n+1)
for i := range graph {
graph[i] = make([]int, n+1)
}
for i := 0; i < m; i++ {
var s, t int
fmt.Scanf("%d %d", &s, &t)
// 使用邻接矩阵表示无向图,1 表示 s 与 t 是相连的
graph[s][t] = 1
}
path = append(path, 1) // 无论什么路径已经是从1节点出发
dfs(graph, 1, n) // 开始遍历
// 输出结果
if len(result) == 0 {
fmt.Println(-1)
} else {
for _, pa := range result {
for i := 0; i < len(pa)-1; i++ {
fmt.Print(pa[i], " ")
}
fmt.Println(pa[len(pa)-1])
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 邻接表写法
package main
import (
"fmt"
)
var result [][]int
var path []int
func dfs(graph [][]int, x, n int) {
if x == n {
temp := make([]int, len(path))
copy(temp, path)
result = append(result, temp)
return
}
for _, i := range graph[x] {
path = append(path, i)
dfs(graph, i, n)
path = path[:len(path)-1]
}
}
func main() {
var n, m int
fmt.Scanf("%d %d", &n, &m)
graph := make([][]int, n+1)
for i := 0; i <= n; i++ {
graph[i] = make([]int, 0)
}
for m > 0 {
var s, t int
fmt.Scanf("%d %d", &s, &t)
graph[s] = append(graph[s], t)
m--
}
path = append(path, 1)
dfs(graph, 1, n)
if len(result) == 0 {
fmt.Println(-1)
} else {
for _, pa := range result {
for i := 0; i < len(pa)-1; i++ {
fmt.Print(pa[i], " ")
}
fmt.Println(pa[len(pa)-1])
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# Rust
# JavaScript
# 邻接矩阵写法
const r1 = require('readline').createInterface({ input: process.stdin });
// 创建readline接口
let iter = r1[Symbol.asyncIterator]();
// 创建异步迭代器
const readline = async ()=>(await iter.next()).value;
let graph;
let N, M;
// 收集符合条件的路径
let result = [];
// 1节点到终点的路径
let path = [];
// 创建邻接矩阵,初始化邻接矩阵
async function initGraph(){
let line;
line = await readline();
[N, M] = line.split(' ').map(i => parseInt(i))
graph = new Array(N + 1).fill(0).map(() => new Array(N + 1).fill(0))
while(M--){
line = await readline()
const strArr = line ? line.split(' ').map(i => parseInt(i)) : undefined
strArr ? graph[strArr[0]][strArr[1]] = 1 : null
}
};
// 深度搜索
function dfs(graph, x, n){
// 当前遍历节点为x, 到达节点为n
if(x == n){
result.push([...path])
return
}
for(let i = 1 ; i <= n ; i++){
if(graph[x][i] == 1){
path.push(i)
dfs(graph, i, n )
path.pop(i)
}
}
};
(async function(){
// 创建邻接矩阵,初始化邻接矩阵
await initGraph();
// 从节点1开始深度搜索
path.push(1);
// 深度搜索
dfs(graph, 1, N );
// 输出
if(result.length > 0){
result.forEach(i => {
console.log(i.join(' '))
})
}else{
console.log(-1)
}
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# 邻接表写法
const r1 = require('readline').createInterface({ input: process.stdin });
// 创建readline接口
let iter = r1[Symbol.asyncIterator]();
// 创建异步迭代器
const readline = async () => (await iter.next()).value;
let graph;
let N, M;
// 收集符合条件的路径
let result = [];
// 1节点到终点的路径
let path = [];
// 创建邻接表,初始化邻接表
async function initGraph() {
let line;
line = await readline();
[N, M] = line.split(' ').map(i => parseInt(i))
graph = new Array(N + 1).fill(0).map(() => new Array())
while (line = await readline()) {
const strArr = line.split(' ').map(i => parseInt(i))
strArr ? graph[strArr[0]].push(strArr[1]) : null
}
};
// 深度搜索
async function dfs(graph, x, n) {
// 当前遍历节点为x, 到达节点为n
if (x == n) {
result.push([...path])
return
}
graph[x].forEach(i => {
path.push(i)
dfs(graph, i, n)
path.pop(i)
})
};
(async function () {
// 创建邻接表,初始化邻接表
await initGraph();
// 从节点1开始深度搜索
path.push(1);
// 深度搜索
dfs(graph, 1, N);
// 输出
if (result.length > 0) {
result.forEach(i => {
console.log(i.join(' '))
})
} else {
console.log(-1)
}
})();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
评论
验证登录状态...