
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!
# Bellman_ford 队列优化算法(又名SPFA)
卡码网:94. 城市间货物运输 I (opens new window)
题目描述
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。
权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。
如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
输入描述
第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v(单向图)。
输出描述
如果能够从城市 1 到连通到城市 n, 请输出一个整数,表示运输成本。如果该整数是负数,则表示实现了盈利。如果从城市 1 没有路径可达城市 n,请输出 "unconnected"。
输入示例:
6 7
5 6 -2
1 2 1
5 3 1
2 5 2
2 4 -3
4 6 4
1 3 5
2
3
4
5
6
7
8
# 背景
《代码随想录》算法视频公开课 (opens new window):图论:学透最短路算法之Bellman-ford算法(队列优化) | 贝尔曼-福特算法(队列优化) (opens new window),相信结合视频再看本篇题解,更有助于大家对本题的理解。
本题我们来系统讲解 Bellman_ford 队列优化算法 ,也叫SPFA算法(Shortest Path Faster Algorithm)。
SPFA的称呼来自 1994年西南交通大学段凡丁的论文,其实Bellman_ford 提出后不久 (20世纪50年代末期) 就有队列优化的版本,国际上不承认这个算法是是国内提出的。 所以国际上一般称呼 该算法为 Bellman_ford 队列优化算法(Queue improved Bellman-Ford)
大家知道以上来历,知道 SPFA 和 Bellman_ford 队列优化算法 指的都是一个算法就好。
如果大家还不够了解 Bellman_ford 算法,强烈建议按照《代码随想录》的顺序学习,否则可能看不懂下面的讲解。
大家可以发现 Bellman_ford 算法每次松弛 都是对所有边进行松弛。
但真正有效的松弛,是基于已经计算过的节点在做的松弛。
给大家举一个例子:
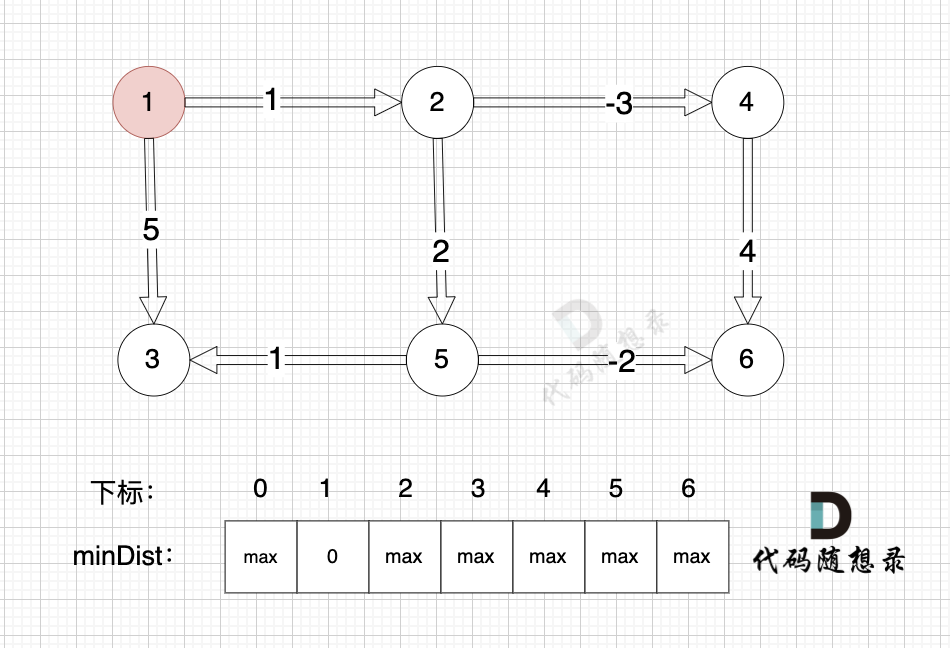
本图中,对所有边进行松弛,真正有效的松弛,只有松弛 边(节点1->节点2) 和 边(节点1->节点3) 。
而松弛 边(节点4->节点6) ,边(节点5->节点3)等等 都是无效的操作,因为 节点4 和 节点 5 都是没有被计算过的节点。
所以 Bellman_ford 算法 每次都是对所有边进行松弛,其实是多做了一些无用功。
只需要对 上一次松弛的时候更新过的节点作为出发节点所连接的边 进行松弛就够了。
基于以上思路,如何记录 上次松弛的时候更新过的节点呢?
用队列来记录。(其实用栈也行,对元素顺序没有要求)
# 模拟过程
接下来来举例这个队列是如何工作的。
以示例给出的所有边为例:
5 6 -2
1 2 1
5 3 1
2 5 2
2 4 -3
4 6 4
1 3 5
2
3
4
5
6
7
我们依然使用minDist数组来表达 起点到各个节点的最短距离,例如minDist[3] = 5 表示起点到达节点3 的最小距离为5
初始化,起点为节点1, 起点到起点的最短距离为0,所以minDist[1] 为 0。 将节点1 加入队列 (下次松弛从节点1开始)
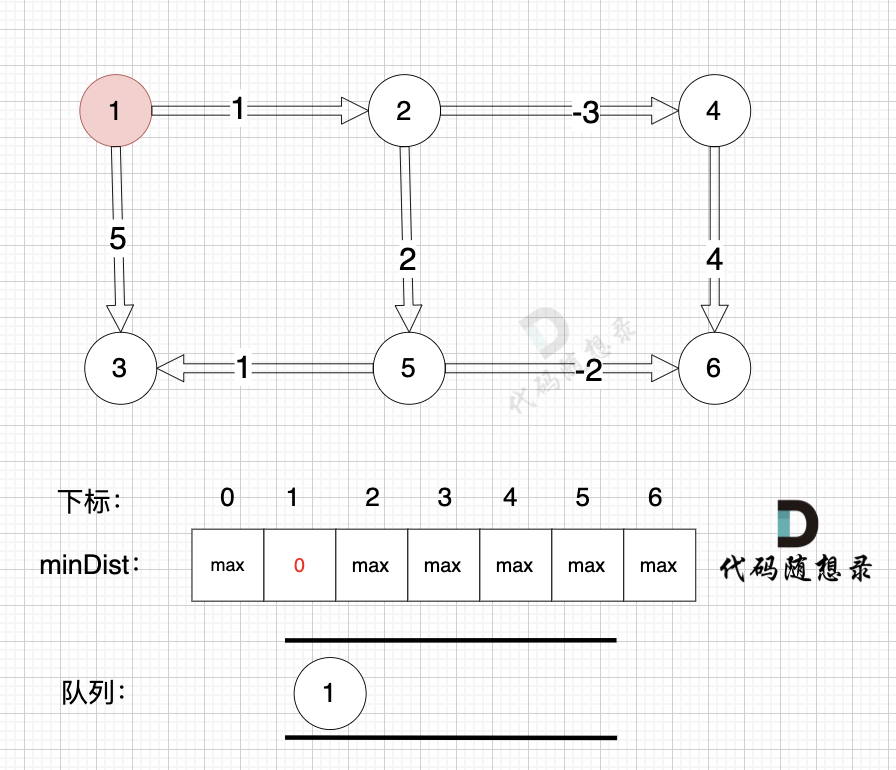
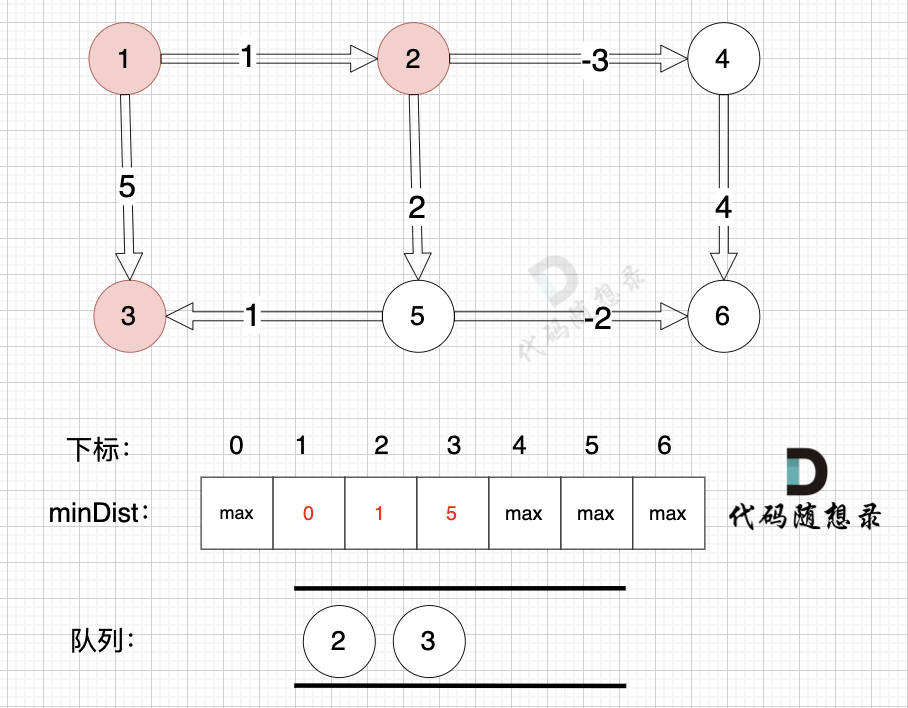
从队列里取出节点1,松弛节点1 作为出发点连接的边(节点1 -> 节点2)和边(节点1 -> 节点3)
边:节点1 -> 节点2,权值为1 ,minDist[2] > minDist[1] + 1 ,更新 minDist[2] = minDist[1] + 1 = 0 + 1 = 1 。
边:节点1 -> 节点3,权值为5 ,minDist[3] > minDist[1] + 5,更新 minDist[3] = minDist[1] + 5 = 0 + 5 = 5。
将节点2、节点3 加入队列,如图:
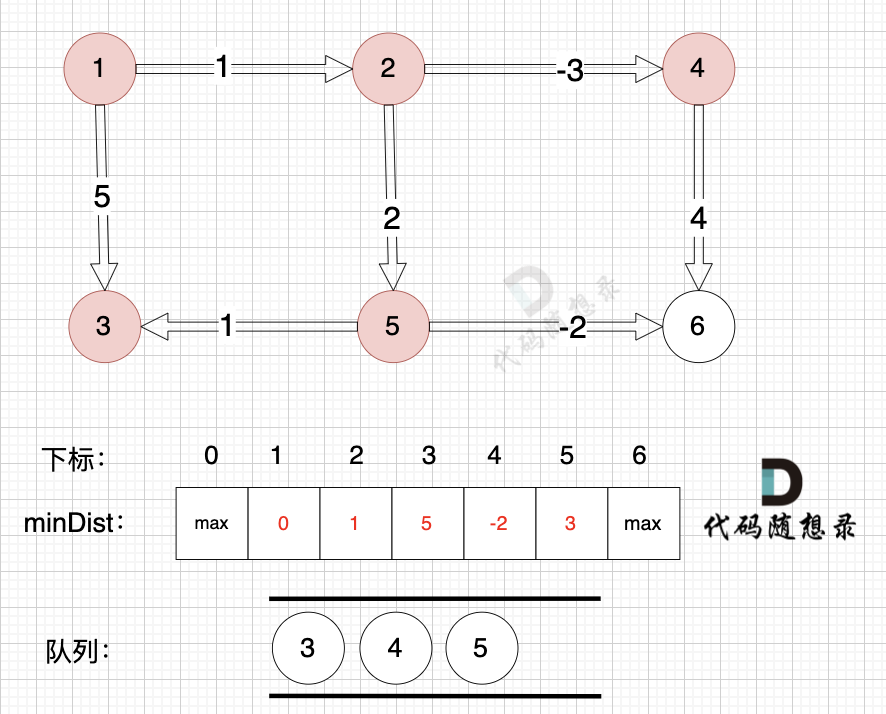
从队列里取出节点2,松弛节点2 作为出发点连接的边(节点2 -> 节点4)和边(节点2 -> 节点5)
边:节点2 -> 节点4,权值为1 ,minDist[4] > minDist[2] + (-3) ,更新 minDist[4] = minDist[2] + (-3) = 1 + (-3) = -2 。
边:节点2 -> 节点5,权值为2 ,minDist[5] > minDist[2] + 2 ,更新 minDist[5] = minDist[2] + 2 = 1 + 2 = 3 。
将节点4,节点5 加入队列,如图:
从队列里出去节点3,松弛节点3 作为出发点连接的边。
因为没有从节点3作为出发点的边,所以这里就从队列里取出节点3就好,不用做其他操作,如图:
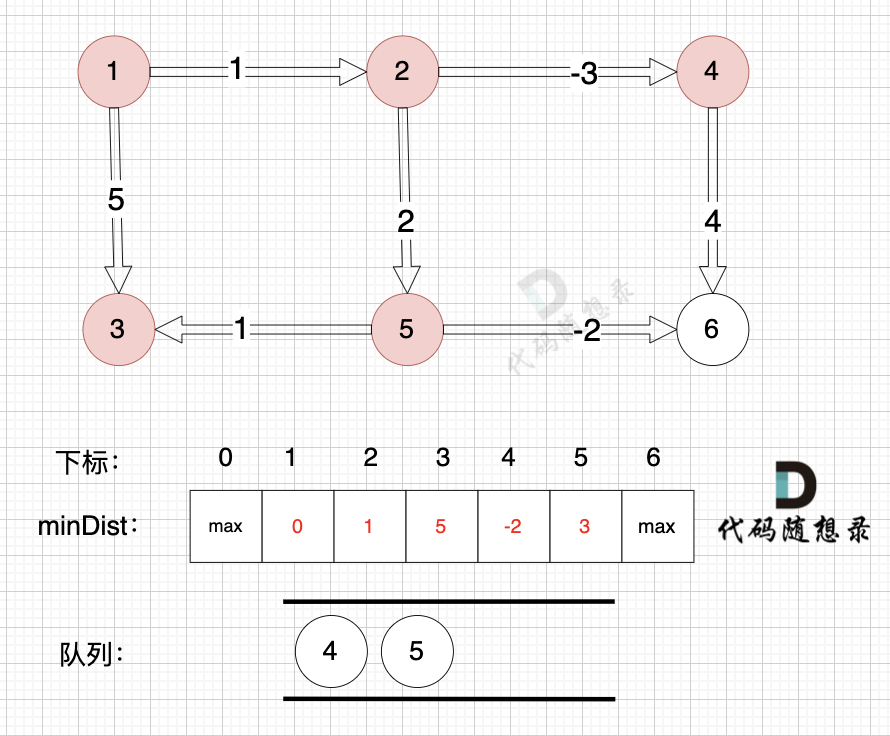
从队列中取出节点4,松弛节点4作为出发点连接的边(节点4 -> 节点6)
边:节点4 -> 节点6,权值为4 ,minDist[6] > minDist[4] + 4,更新 minDist[6] = minDist[4] + 4 = -2 + 4 = 2 。
将节点6加入队列
如图:
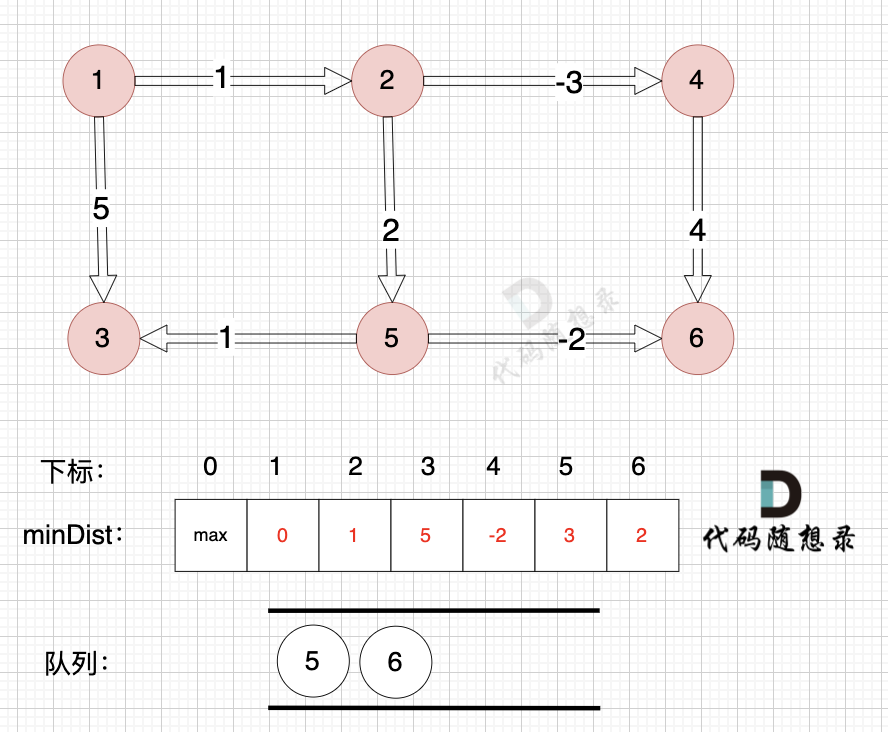
从队列中取出节点5,松弛节点5作为出发点连接的边(节点5 -> 节点3),边(节点5 -> 节点6)
边:节点5 -> 节点3,权值为1 ,minDist[3] > minDist[5] + 1 ,更新 minDist[3] = minDist[5] + 1 = 3 + 1 = 4
边:节点5 -> 节点6,权值为-2 ,minDist[6] > minDist[5] + (-2) ,更新 minDist[6] = minDist[5] + (-2) = 3 - 2 = 1
如图,将节点3加入队列,因为节点6已经在队列里,所以不用重复添加

所以我们在加入队列的过程可以有一个优化,用visited数组记录已经在队列里的元素,已经在队列的元素不用重复加入
从队列中取出节点6,松弛节点6 作为出发点连接的边。
节点6作为终点,没有可以出发的边。
同理从队列中取出节点3,也没有可以出发的边
所以直接从队列中取出,如图:
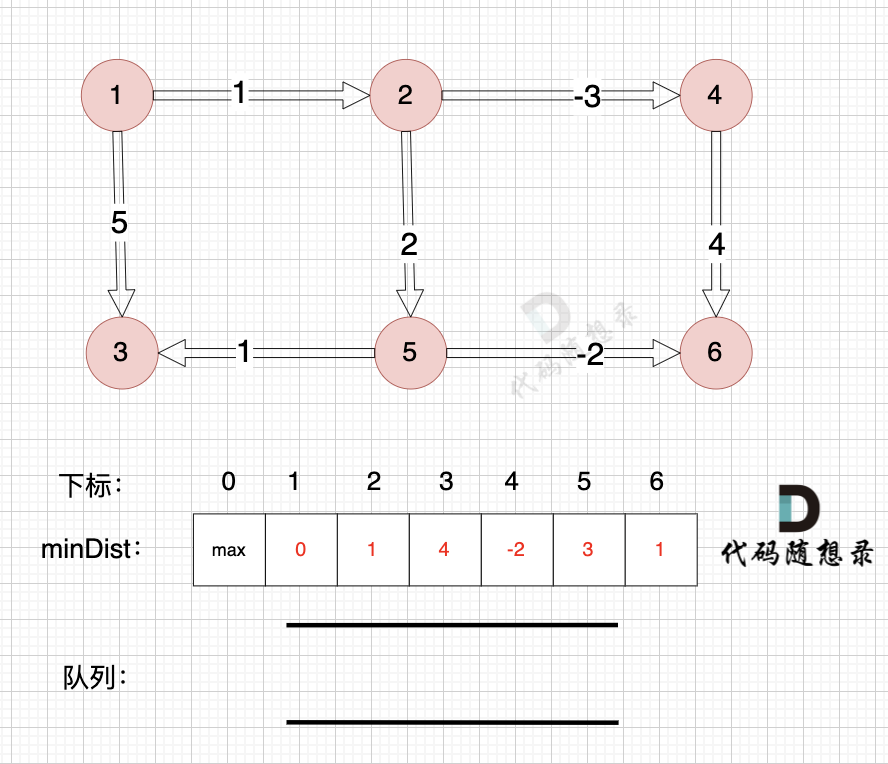
这样我们就完成了基于队列优化的bellman_ford的算法模拟过程。
大家可以发现 基于队列优化的算法,要比bellman_ford 算法 减少很多无用的松弛情况,特别是对于边数众多的大图 优化效果明显。
了解了大体流程,我们再看代码应该怎么写。
在上面模拟过程中,我们每次都要知道 一个节点作为出发点连接了哪些节点。
如果想方便知道这些数据,就需要使用邻接表来存储这个图,如果对于邻接表不了解的话,可以看 kama0047.参会dijkstra堆 中 图的存储 部分。
整体代码如下:
#include <iostream>
#include <vector>
#include <queue>
#include <list>
#include <climits>
using namespace std;
struct Edge { //邻接表
int to; // 链接的节点
int val; // 边的权重
Edge(int t, int w): to(t), val(w) {} // 构造函数
};
int main() {
int n, m, p1, p2, val;
cin >> n >> m;
vector<list<Edge>> grid(n + 1);
vector<bool> isInQueue(n + 1); // 加入优化,已经在队里里的元素不用重复添加
// 将所有边保存起来
for(int i = 0; i < m; i++){
cin >> p1 >> p2 >> val;
// p1 指向 p2,权值为 val
grid[p1].push_back(Edge(p2, val));
}
int start = 1; // 起点
int end = n; // 终点
vector<int> minDist(n + 1 , INT_MAX);
minDist[start] = 0;
queue<int> que;
que.push(start);
while (!que.empty()) {
int node = que.front(); que.pop();
isInQueue[node] = false; // 从队列里取出的时候,要取消标记,我们只保证已经在队列里的元素不用重复加入
for (Edge edge : grid[node]) {
int from = node;
int to = edge.to;
int value = edge.val;
if (minDist[to] > minDist[from] + value) { // 开始松弛
minDist[to] = minDist[from] + value;
if (isInQueue[to] == false) { // 已经在队列里的元素不用重复添加
que.push(to);
isInQueue[to] = true;
}
}
}
}
if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点
else cout << minDist[end] << endl; // 到达终点最短路径
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# 效率分析
队列优化版Bellman_ford 的时间复杂度 并不稳定,效率高低依赖于图的结构。
例如 如果是一个双向图,且每一个节点和所有其他节点都相连的话,那么该算法的时间复杂度就接近于 Bellman_ford 的 O(N * E) N 为节点数量,E为边的数量。
在这种图中,每一个节点都会重复加入队列 n - 1次,因为 这种图中 每个节点 都有 n-1 条指向该节点的边,每条边指向该节点,就需要加入一次队列。(如果这里看不懂,可以在重温一下代码逻辑)
至于为什么 双向图且每一个节点和所有其他节点都相连的话,每个节点 都有 n-1 条指向该节点的边, 我再来举个例子,如图:
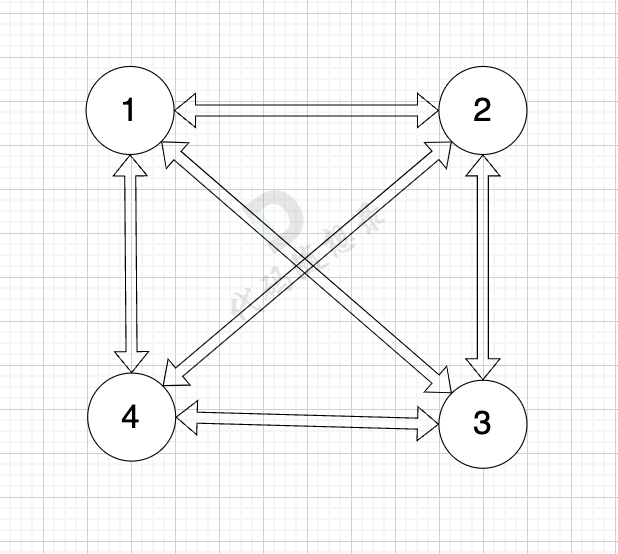
图中 每个节点都与其他所有节点相连,节点数n 为 4,每个节点都有3条指向该节点的边,即入度为3。
n为其他数值的时候,也是一样的。
当然这种图是比较极端的情况,也是最稠密的图。
所以如果图越稠密,则 SPFA的效率越接近与 Bellman_ford。
反之,图越稀疏,SPFA的效率就越高。
一般来说,SPFA 的时间复杂度为 O(K * N) K 为不定值,因为 节点需要计入几次队列取决于 图的稠密度。
如果图是一条线形图且单向的话,每个节点的入度为1,那么只需要加入一次队列,这样时间复杂度就是 O(N)。
所以 SPFA 在最坏的情况下是 O(N * E),但 一般情况下 时间复杂度为 O(K * N)。
尽管如此,以上分析都是 理论上的时间复杂度分析。
并没有计算 出队列 和 入队列的时间消耗。 因为这个在不同语言上 时间消耗也是不一定的。
以C++为例,以下两段代码理论上,时间复杂度都是 O(n) :
for (long long i = 0; i < n; i++) {
k++;
}
2
3
4
for (long long i = 0; i < n; i++) {
que.push(i);
que.front();
que.pop();
}
2
3
4
5
6
在 MacBook Pro (13-inch, M1, 2020) 机器上分别测试这两段代码的时间消耗情况:
- n = 10^4,第一段代码的时间消耗:1ms,第二段代码的时间消耗: 4 ms
- n = 10^5,第一段代码的时间消耗:1ms,第二段代码的时间消耗: 13 ms
- n = 10^6,第一段代码的时间消耗:4ms,第二段代码的时间消耗: 59 ms
- n = 10^7,第一段代码的时间消耗: 24ms,第二段代码的时间消耗: 463 ms
- n = 10^8,第一段代码的时间消耗: 135ms,第二段代码的时间消耗: 4268 ms
在这里就可以看出 出队列和入队列 其实也是十分耗时的。
SPFA(队列优化版Bellman_ford) 在理论上 时间复杂度更胜一筹,但实际上,也要看图的稠密程度,如果 图很大且非常稠密的情况下,虽然 SPFA的时间复杂度接近Bellman_ford,但实际时间消耗 可能是 SPFA耗时更多。
针对这种情况,我在后面题目讲解中,会特别加入稠密图的测试用例来给大家讲解。
# 拓展
这里可能有录友疑惑,while (!que.empty()) 队里里 会不会造成死循环? 例如 图中有环,这样一直有元素加入到队列里?
其实有环的情况,要看它是 正权回路 还是 负权回路。
题目描述中,已经说了,本题没有 负权回路 。
如图:
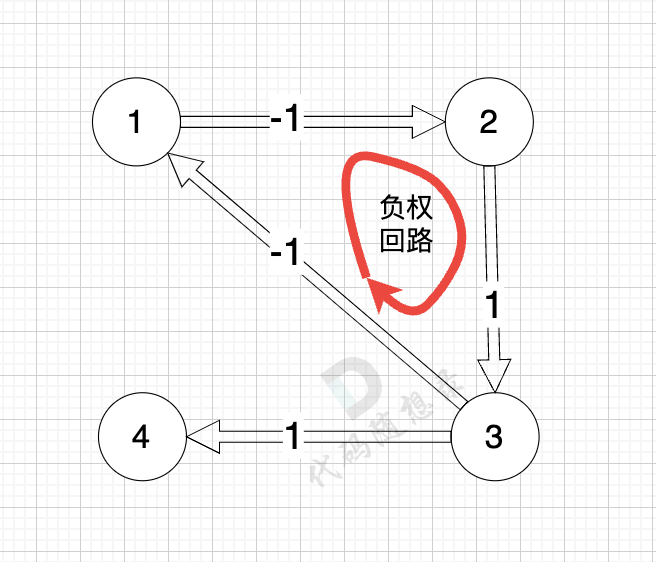
正权回路 就是有环,但环的总权值为正数。
在有环且只有正权回路的情况下,即使元素重复加入队列,最后,也会因为 所有边都松弛后,节点数值(minDist数组)不在发生变化了 而终止。
(而且有重复元素加入队列是正常的,多条路径到达同一个节点,节点必要要选择一个最短的路径,而这个节点就会重复加入队列进行判断,选一个最短的)
在0094.城市间货物运输I 中我们讲过对所有边 最多松弛 n -1 次,就一定可以求出所有起点到所有节点的最小距离即 minDist数组。
即使再松弛n次以上, 所有起点到所有节点的最小距离(minDist数组) 不会再变了。 (这里如果不理解,建议认真看0094.城市间货物运输I讲解)
所以本题我们使用队列优化,有元素重复加入队列,也会因为最后 minDist数组 不会在发生变化而终止。
节点再加入队列,需要有松弛的行为, 而 每个节点已经都计算出来 起点到该节点的最短路径,那么就不会有 执行这个判断条件if (minDist[to] > minDist[from] + value),从而不会有新的节点加入到队列。
但如果本题有 负权回路,那情况就不一样了,我在下一题目讲解中,会重点讲解 负权回路 带来的变化。
# 其他语言版本
# Java
import java.util.*;
public class Main {
// Define an inner class Edge
static class Edge {
int from;
int to;
int val;
public Edge(int from, int to, int val) {
this.from = from;
this.to = to;
this.val = val;
}
}
public static void main(String[] args) {
// Input processing
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<List<Edge>> graph = new ArrayList<>();
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
graph.get(from).add(new Edge(from, to, val));
}
// Declare the minDist array to record the minimum distance form current node to the original node
int[] minDist = new int[n + 1];
Arrays.fill(minDist, Integer.MAX_VALUE);
minDist[1] = 0;
// Declare a queue to store the updated nodes instead of traversing all nodes each loop for more efficiency
Queue<Integer> queue = new LinkedList<>();
queue.offer(1);
// Declare a boolean array to record if the current node is in the queue to optimise the processing
boolean[] isInQueue = new boolean[n + 1];
while (!queue.isEmpty()) {
int curNode = queue.poll();
isInQueue[curNode] = false; // Represents the current node is not in the queue after being polled
for (Edge edge : graph.get(curNode)) {
if (minDist[edge.to] > minDist[edge.from] + edge.val) { // Start relaxing the edge
minDist[edge.to] = minDist[edge.from] + edge.val;
if (!isInQueue[edge.to]) { // Don't add the node if it's already in the queue
queue.offer(edge.to);
isInQueue[edge.to] = true;
}
}
}
}
// Outcome printing
if (minDist[n] == Integer.MAX_VALUE) {
System.out.println("unconnected");
} else {
System.out.println(minDist[n]);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# Python
import collections
def main():
n, m = map(int, input().strip().split())
edges = [[] for _ in range(n + 1)]
for _ in range(m):
src, dest, weight = map(int, input().strip().split())
edges[src].append([dest, weight])
minDist = [float("inf")] * (n + 1)
minDist[1] = 0
que = collections.deque([1])
visited = [False] * (n + 1)
visited[1] = True
while que:
cur = que.popleft()
visited[cur] = False
for dest, weight in edges[cur]:
if minDist[cur] != float("inf") and minDist[cur] + weight < minDist[dest]:
minDist[dest] = minDist[cur] + weight
if visited[dest] == False:
que.append(dest)
visited[dest] = True
if minDist[-1] == float("inf"):
return "unconnected"
return minDist[-1]
if __name__ == "__main__":
print(main())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# Go
# Rust
# JavaScript
async function main() {
// 輸入
const rl = require('readline').createInterface({ input: process.stdin })
const iter = rl[Symbol.asyncIterator]()
const readline = async () => (await iter.next()).value
const [n, m] = (await readline()).split(" ").map(Number)
const grid = {}
for (let i = 0 ; i < m ; i++) {
const [src, desc, w] = (await readline()).split(" ").map(Number)
if (grid.hasOwnProperty(src)) {
grid[src].push([desc, w])
} else {
grid[src] = [[desc, w]]
}
}
const minDist = Array.from({length: n + 1}, () => Number.MAX_VALUE)
// 起始點
minDist[1] = 0
const q = [1]
const visited = Array.from({length: n + 1}, () => false)
while (q.length) {
const src = q.shift()
const neighbors = grid[src]
visited[src] = false
if (neighbors) {
for (const [desc, w] of neighbors) {
if (minDist[src] !== Number.MAX_VALUE
&& minDist[src] + w < minDist[desc]) {
minDist[desc] = minDist[src] + w
if (!visited[desc]) {
q.push(desc)
visited[desc] = true
}
}
}
}
}
// 輸出
if (minDist[n] === Number.MAX_VALUE) {
console.log('unconnected')
} else {
console.log(minDist[n])
}
}
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
评论
验证登录状态...