
# 49. 字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
解释:
- 在 strs 中没有字符串可以通过重新排列来形成
"bat"。 - 字符串
"nat"和"tan"是字母异位词,因为它们可以重新排列以形成彼此。 - 字符串
"ate","eat"和"tea"是字母异位词,因为它们可以重新排列以形成彼此。
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
提示:
1 <= strs.length <= 10^40 <= strs[i].length <= 100strs[i]仅包含小写字母
# 思路
本题本质是要把具备某一特征的字符串,放到同一个集合里。
这里就需要做映射,也就是把某一特征的字符串都映射到相同集合里。
那么想到映射,就应该想到哈希表了。
这时候,就要想,使用什么样的哈希表。
本题再求 相同异位词的集合,那么 相同异位词有一个特征,即使字符串里的字母都是一样的,仅仅顺序不同而已。
所以我们把异位词里的字符做个排序,那么如果是两个字符串是异位词,那么排序后 两个字符串就是相同的了。
我们将排序后相同的字符串的原字符串都要放在同一个集合里。
这里,我们就可以想到用什么哈希表了,也就是map。
map的key是排序后的字符创,map的value 是对应的原串。
key要求不能重复,因为排序后相同的字符串要唯一,而value需要是一个集合,我们把排序后字符串对应的原串要放在一起。
所以 map的数据结构应该是 map <string,vector<string> >
这里的vector是 C++里的数组。
这样 我们就把排序后相同字符串对应的原串都放在一个数组里。
这里还有一个问题,就是 key不能重复,所以我们要选择 unordered_map
unordered_map是C++里一个数据结构,其他语言录友了解特性,使用自己的语言即可
关于 C++里 不同map的特性,在代码随想录两数之和里有讲解
现在思路就有眉目了,我们只需要遍历一遍字符串数组,将每一个字符串排序,作为map的key,排序后相同的字符串自然放到了 key对应的 value集合里。
# 模拟过程如下:
eat 排序后为 aet, 将 eat 放在 key为 aet 的map中:

tea 排序后 为 aet,将 tea 放在 key 为 aet的map中:
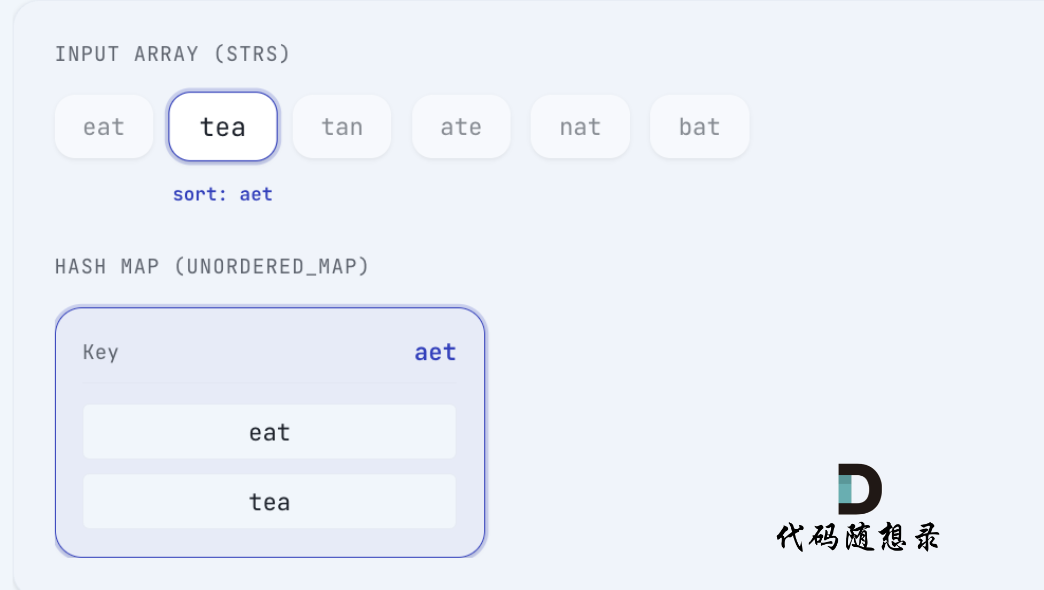
tan 排序后 为 ant,将 tan 放在 key 为 ant 的map中:
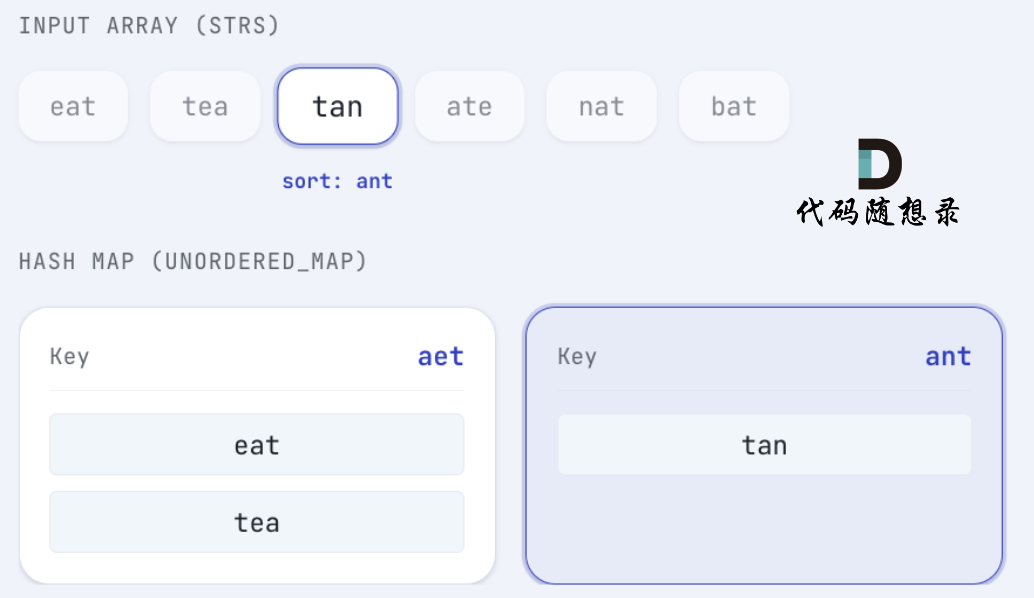
ate排序后为aet,将 ate 放在 key 为aet的map中:

nat 排序后 为 ant ,将 nat 放在 key为 ant 的 map中:
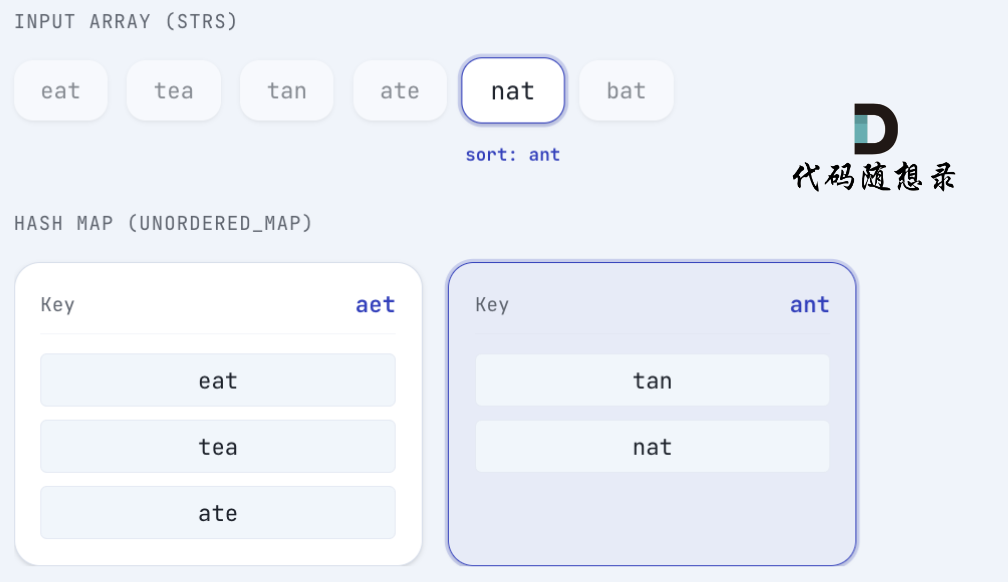
bat 排序后 为 abt,将 bat 放在 key为 abt 的map 中:
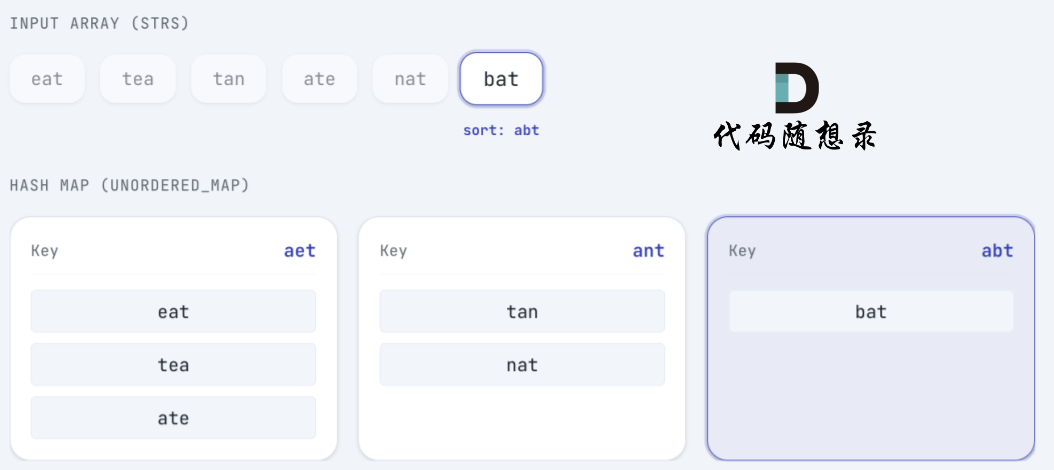
最后,map 就根据key,帮我们分门别类,将所有字符串按照 字符异位词分组。
代码如下:
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> result;
unordered_map <string,vector<string> > umap;
for (int i = 0; i < strs.size(); i++) {
string tmp = strs[i];
sort(tmp.begin(), tmp.end());
umap[tmp].push_back(strs[i]);
}
for (auto& collection : umap) result.push_back(collection.second);
return result;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
时间复杂度:O(nklogk) ,k为每个单词的长度
# 视频讲解
https://anagramanim-yercubvi.manus.space/ (opens new window)
# 其他语言
# python3
from typing import List
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
umap = defaultdict(list)
for s in strs:
key = ''.join(sorted(s))
umap[key].append(s)
return list(umap.values())
2
3
4
5
6
7
8
9
10
# Java
import java.util.*;
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
char[] arr = s.toCharArray();
Arrays.sort(arr);
String key = new String(arr);
map.computeIfAbsent(key, k -> new ArrayList<>()).add(s);
}
return new ArrayList<>(map.values());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Go
package main
import (
"sort"
)
func groupAnagrams(strs []string) [][]string {
umap := make(map[string][]string)
for _, s := range strs {
chars := []byte(s)
sort.Slice(chars, func(i, j int) bool { return chars[i] < chars[j] })
key := string(chars)
umap[key] = append(umap[key], s)
}
result := make([][]string, 0, len(umap))
for _, group := range umap {
result = append(result, group)
}
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# JS
/**
* @param {string[]} strs
* @return {string[][]}
*/
var groupAnagrams = function(strs) {
const map = new Map();
for (const s of strs) {
const key = s.split('').sort().join('');
if (!map.has(key)) {
map.set(key, []);
}
map.get(key).push(s);
}
return Array.from(map.values());
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 与代码随想录联系
我在代码随想录哈希表章节里,详细讲解过,什么时候用数组,什么时候用set,什么时候用map。
如果想进一步学习,可以看一下代码随想录哈希表章节 (opens new window),刷前四节,就可以理解了

同时大家在做这道题目的时候,一定会想到,代码随想录哈希表章节:242.有效的字母异位词 。
如果按照242.有效的字母异位词 思路来,就是把 242.有效的字母异位词 的题目代码抽离出来一个函数,专门判断两个字是否是 异位词。
然后两个for循环遍历 本题 的数组,寻找 异位词集合。
代码如下:
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for (int i = 0; i < s.size(); i++) {
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[s[i] - 'a']++;
}
for (int i = 0; i < t.size(); i++) {
record[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (record[i] != 0) {
// record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
// record数组所有元素都为零0,说明字符串s和t是字母异位词
return true;
}
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> result;
set<string> flag; // 标记哪个已经添加到结果集里
for (int i = 0; i < strs.size(); i++){
if (flag.find(strs[i]) != flag.end()) continue; // 已经在结果集里直接跳过
vector<string> collection;
collection.push_back(strs[i]);
flag.insert(strs[i]);
// 开始寻找和 strs[i] 的字母异位词
for (int j = i + 1; j < strs.size(); j++){
if (isAnagram(strs[i], strs[j])) {
collection.push_back(strs[j]);
flag.insert(strs[j]);
}
}
result.push_back(collection);
}
return result;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
大家提交后,会发现超时了。本代码的时间复杂度 O(n * n * n)
本题核心是要灵活使用map
评论
验证登录状态...