
# 560. 和为 K 的子数组
给定一个整数数组 nums 和一个整数 k,请你统计并返回 该数组中和为 k 的连续子数组的个数。
示例 1:
输入:nums = [1,1,1], k = 2
输出:2
示例 2:
输入:nums = [1,2,3], k = 3
输出:2
提示:
- 1 <= nums.length <= 2 * 10^4
- -1000 <= nums[i] <= 1000
- -10^7 <= k <= 10^7
# 暴力解法
枚举所有子数组。
最直观的想法,就是:
- 枚举所有可能的子数组
[i, j] - 计算区间和
- 判断是否等于
k
代码思路(两层循环)
for i in [0..n-1]:
sum = 0
for j in [i..n-1]:
sum += nums[j]
if sum == k:
result++
2
3
4
5
6
时间复杂度
- 时间复杂度:
O(n^2) - 空间复杂度:
O(1)
当 n 最大到 2 万时,O(n^2) 已经明显超时。
所以我们必须想办法 避免重复计算子数组的和。
# 用双指针 / 滑动窗口?
很多录友看到本题第一反应是:连续子数组 + 求和 = 滑动窗口?
但本题 不能用双指针,原因非常关键。
双指针的前提条件
滑动窗口之所以能用,通常依赖一个前提:
窗口扩大时,区间和单调变化;窗口收缩时,区间和也单调变化
比如:
- 全是正数
- 或者满足某种单调性
本题的问题
nums 中 可能包含负数,例如:
nums = [1, -1, 1], k = 1
你会发现:
- 右指针右移,区间和 可能变大,也可能变小
- 左指针右移,区间和 同样不可控
区间和完全不具有单调性
因此,无法通过「和大了就缩左边,小了就扩右边」这种规则来控制窗口
所以 只要数组中有负数,本题就不能用滑动窗口 / 双指针。
这是一个非常典型的「反双指针」题目。
# 前缀和
既然暴力慢,是因为重复算区间和,那就想办法提前算好。
# 什么是前缀和?
定义:
preSum[i] = nums[0] + nums[1] + ... + nums[i]
那么任意区间 [l, r] 的和为:
sum(l, r) = preSum[r] - preSum[l - 1]
例如,我们要统计 vec[i] 这个数组上的区间和。
我们先做累加,即 p[i] 表示 下标 0 到 i 的 vec[i] 累加 之和。
如图:
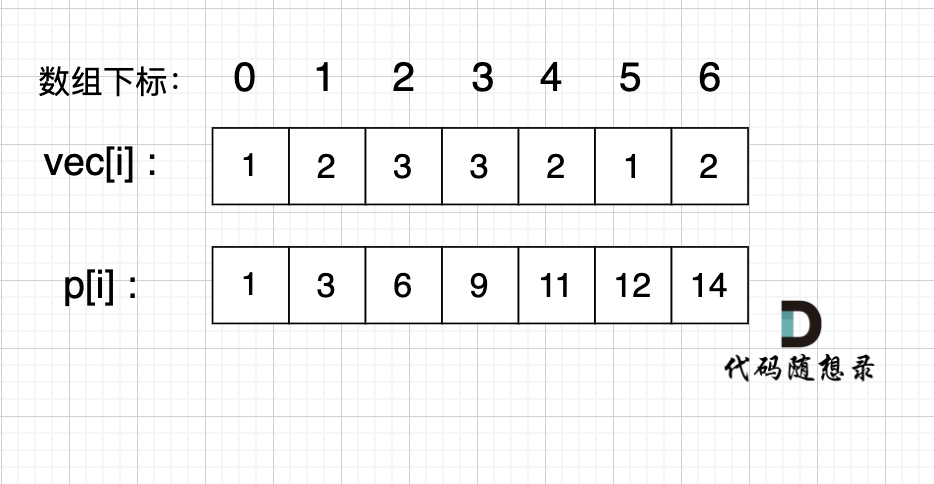
如果,我们想统计,在vec数组上 下标 2 到下标 5 之间的累加和,那是不是就用 p[5] - p[1] 就可以了。
为什么呢?
p[1] = vec[0] + vec[1];
p[5] = vec[0] + vec[1] + vec[2] + vec[3] + vec[4] + vec[5];
p[5] - p[1] = vec[2] + vec[3] + vec[4] + vec[5];
这不就是我们要求的 下标 2 到下标 5 之间的累加和吗。
如图所示:
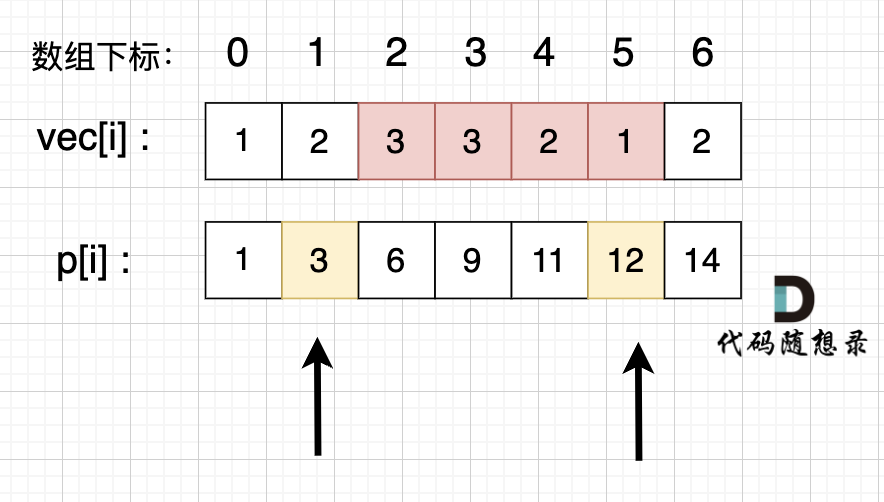
p[5] - p[1] 就是 红色部分的区间和。
而 p 数组是我们之前就计算好的累加和,所以后面每次求区间和的之后 我们只需要 O(1) 的操作。
特别注意: 在使用前缀和求解的时候,要特别注意 求解区间。
如上图,如果我们要求 区间下标 [2, 5] 的区间和,那么应该是 p[5] - p[1],而不是 p[5] - p[2]。
很多录友在使用前缀和的时候,分不清前缀和的区间,建议画一画图,模拟一下 思路会更清晰。
如何用在本题?
如果:
preSum[r] - preSum[l - 1] = k
等价于:
preSum[l - 1] = preSum[r] - k
问题转化为:在遍历到某个位置 r 时,**之前是否出现过前缀和等于 ****preSum[r] - k**
# 前缀和 + 哈希表
核心思想
- 一边遍历数组
- 一边记录「某个前缀和出现了多少次」
- 每次判断:
**prefixSum - k**** 是否出现过**
# C++代码如下:
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
// 记录前缀和出现的次数
unordered_map<int, int> prefixCount;
// 前缀和为 0 的情况,初始化为 1 次
prefixCount[0] = 1;
int prefixSum = 0;
int result = 0;
for (int i = 0; i < nums.size(); i++) {
// 更新当前前缀和
prefixSum += nums[i];
// 如果存在 prefixSum - k
// 说明存在子数组和为 k
if (prefixCount.count(prefixSum - k)) {
result += prefixCount[prefixSum - k];
}
// 记录当前前缀和
prefixCount[prefixSum]++;
}
return result;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
- 时间复杂度:
O(n) - 空间复杂度:
O(n)
# 常见疑问
为什么要 prefixCount[0] = 1?
这一步非常容易漏,但极其重要:
- 表示「从数组起点开始的子数组」
- 当
prefixSum == k时,
prefixSum - k == 0,正好能被统计到,这是边界处理技巧。需要大家模拟一下,才知道 prefixCount[0] 应该如何初始化。
为什么是result += prefixCount[prefixSum - k];?而不是 result += 1;
因为:同一个前缀和可能出现多次,每一次都代表一种合法的子数组起点。
举个例子,如果 nums = [1,-1,0] ,k=0, 有多少子数组等0呢。 如果要是 result += 1; 计算的结果就是2
而正确的结果是3 ,因为三个子数组 [1,-1] [0] 还有 [1,-1,0] 。
所以这里不是 +1,而是 加出现次数
# 其他语言版本
# Python3
class Solution:
def subarraySum(self, nums: list[int], k: int) -> int:
# prefixCount:记录「某个前缀和出现的次数」
prefixCount = {0: 1} # 前缀和为 0 的情况,初始化为 1 次
prefixSum = 0 # 当前前缀和
result = 0 # 结果:和为 k 的子数组个数
for num in nums:
# 更新当前前缀和
prefixSum += num
# 如果之前出现过 prefixSum - k
# 说明存在子数组和为 k
if prefixSum - k in prefixCount:
result += prefixCount[prefixSum - k]
# 记录当前前缀和出现的次数
prefixCount[prefixSum] = prefixCount.get(prefixSum, 0) + 1
return result
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Java
class Solution {
public int subarraySum(int[] nums, int k) {
// prefixCount:记录前缀和出现的次数
Map<Integer, Integer> prefixCount = new HashMap<>();
// 前缀和为 0 的情况,初始化为 1 次
prefixCount.put(0, 1);
int prefixSum = 0;
int result = 0;
for (int num : nums) {
// 更新当前前缀和
prefixSum += num;
// 如果存在 prefixSum - k
// 说明存在子数组和为 k
if (prefixCount.containsKey(prefixSum - k)) {
result += prefixCount.get(prefixSum - k);
}
// 记录当前前缀和出现的次数
prefixCount.put(prefixSum, prefixCount.getOrDefault(prefixSum, 0) + 1);
}
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# GO
func subarraySum(nums []int, k int) int {
// prefixCount:记录前缀和出现的次数
prefixCount := make(map[int]int)
// 前缀和为 0 的情况,初始化为 1 次
prefixCount[0] = 1
prefixSum := 0
result := 0
for _, num := range nums {
// 更新当前前缀和
prefixSum += num
// 如果存在 prefixSum - k
// 说明存在子数组和为 k
if count, ok := prefixCount[prefixSum-k]; ok {
result += count
}
// 记录当前前缀和出现的次数
prefixCount[prefixSum]++
}
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Javascript
var subarraySum = function(nums, k) {
// prefixCount:记录前缀和出现的次数
const prefixCount = new Map();
// 前缀和为 0 的情况,初始化为 1 次
prefixCount.set(0, 1);
let prefixSum = 0;
let result = 0;
for (let num of nums) {
// 更新当前前缀和
prefixSum += num;
// 如果存在 prefixSum - k
// 说明存在子数组和为 k
if (prefixCount.has(prefixSum - k)) {
result += prefixCount.get(prefixSum - k);
}
// 记录当前前缀和出现的次数
prefixCount.set(prefixSum, (prefixCount.get(prefixSum) || 0) + 1);
}
return result;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 与代码随想录联系
代码随想录在数组章节有一个题目是 区间和 (opens new window) 讲的就是前缀和的思路,本题算是在区间和的基础上,再加一个哈希表的逻辑,算是稍稍进阶一点。
如果大家做过 代码随想录数组章节和哈希表章节,解决本题问题不大。
评论
验证登录状态...