
# 3. 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。注意 "bca" 和 "cab" 也是正确答案。
2
3
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
2
3
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
2
3
4
提示:
0 <= s.length <= 5 * 10^4s由英文字母、数字、符号和空格组成
# 思路
# 暴力想法
大家可能第一反应通常是:
- 枚举所有子串
s[i..j] - 检查这个子串有没有重复字符
- 取最大长度
但是检查重复本身就要 O(n),子串数量又是 O(n²),整体就是 O(n³)(或优化到 O(n²) 但仍容易超时)。
这个做法里有很多**重复检查。 **
如果相邻区间之间只有“增一个、减一个”的差别,那就要考虑滑动窗口。
# 滑动窗口
滑动窗口(双指针)
我们用两个指针维护一个窗口 [l, r]:
r向右扩展窗口(探索更长的子串)- 一旦窗口里出现重复字符,就移动
l缩小窗口,直到窗口再次合法
最终过程中记录窗口最大长度即可。
关键难点:出现重复字符时,l 怎么跳?
一些录友会写成:
- 重复了就
l++慢慢挪
但这样会导致整体可能退化到 O(n²)。
其实我们可以 能跳就跳!
用哈希表记录每个字符最近一次出现的位置:
umap
当 s[r] 重复出现时(即 s[r] 在 map 里存在):
- 说明窗口中之前某个位置出现过同样的字符
- 为了让窗口重新“无重复”,
l必须跳到 上一次出现位置的下一位
也就是:
l = umap[s[r]] + 1
但还有一个坑:
l 只能右移,不能左移!
比如:
当前 l 已经在更右边了,而 umap[s[r]] + 1 反而更小,这时不能把 l 往回拉。
所以,取一个最大值:
l = max(l, umap[s[r]] + 1)
# 图示
1、初始化,右指针 r = 0, 左指针l = 0 用umap记录每个字符最近出现的位置,umap[s[r]] = r即 umap[a] = 0,此时 无重复字符的最长子串 result = max(result, r - l + 1) = 1.
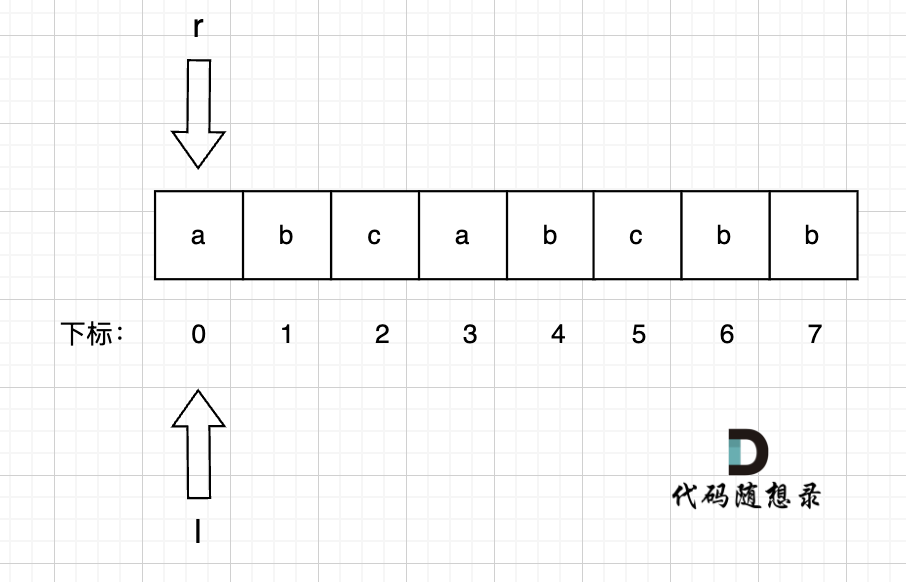
2、右指针 r = 1, 左指针l = 0 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即
umap[a] = 0
umap[b] = 1
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 2
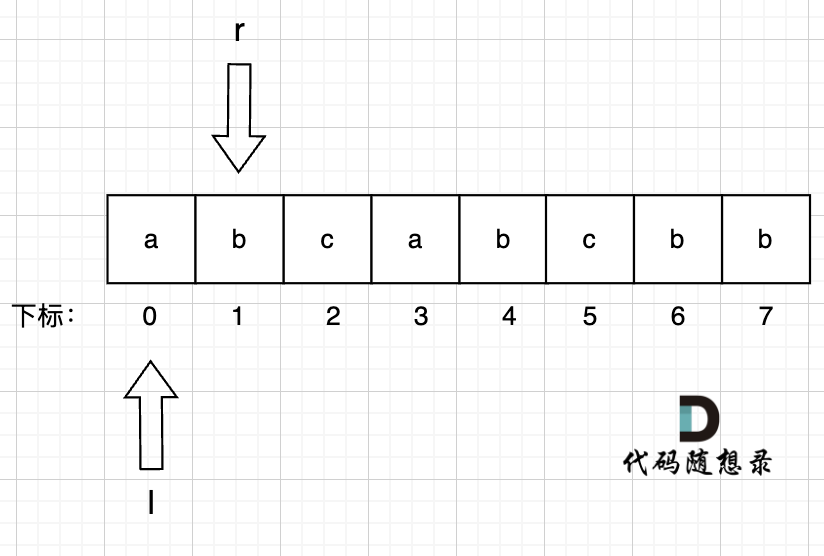
3、右指针 r = 2, 左指针l = 0 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即:
umap[a] = 0
umap[b] = 1
umap[c] = 2
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 3
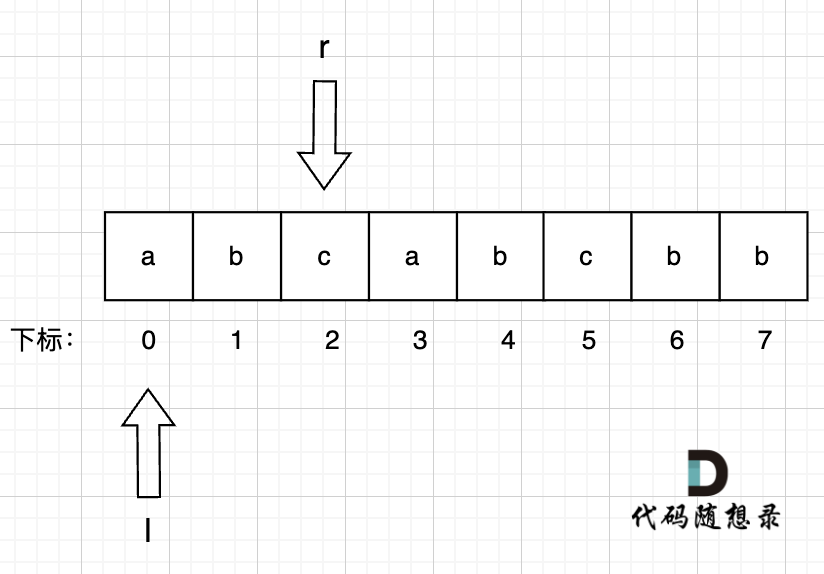
4、右指针 r = 3, 此时右指针指向的位置即s[r] 即 s[3] = a,而a 在 umap里出现过,umap[a] = 0 即 上次a出现的位置是下标0。此时说明出现重复字符了,那么此时l就应该移动,减小窗口,左指针l = max(l, umap[s[r]] + 1) = 1 (这里为什么用了max,上面的讲解已经讲过), 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即:
umap[a] = 3
umap[b] = 1
umap[c] = 2
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 3
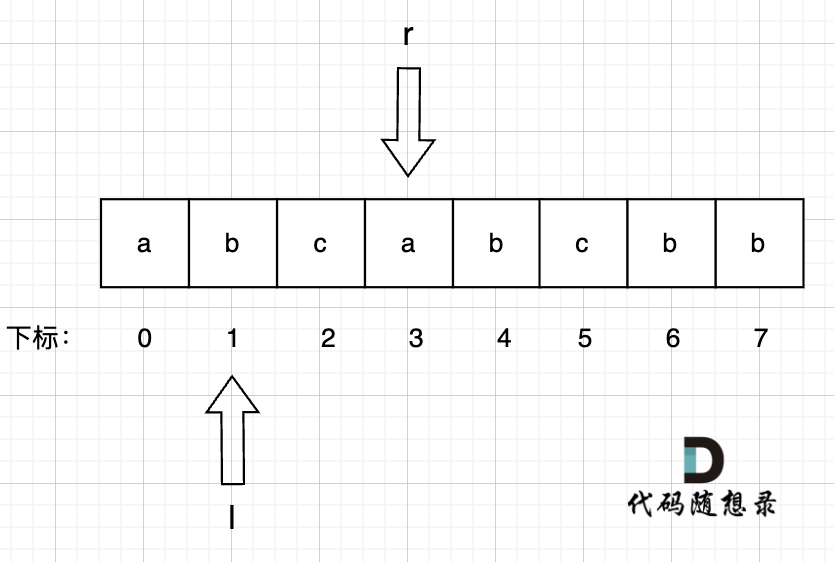
5、右指针 r = 4, 此时右指针指向的位置即s[r] 即 s[4] = b,而b 在 umap里出现过,umap[b] = 1 即 上次b出现的位置是下标1。
此时说明出现重复字符了,那么l就应该移动,减小窗口,左指针l = max(l, umap[s[r]] + 1) = 2 , 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即:
umap[a] = 3
umap[b] = 4
umap[c] = 2
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 3
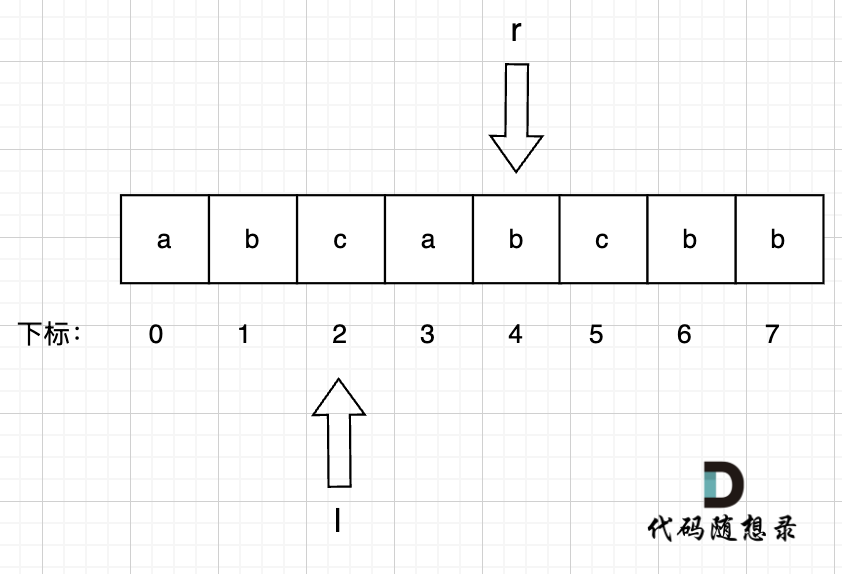
6、右指针 r = 5, 此时右指针指向的位置即s[r] 即 s[5] = c,而c 在 umap里出现过,umap[c] = 2 即 上次c出现的位置是下标2。
此时说明出现重复字符了,那么l就应该移动,减小窗口,左指针l = max(l, umap[s[r]] + 1) = 3 , 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即:
umap[a] = 3
umap[b] = 4
umap[c] = 5
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 3
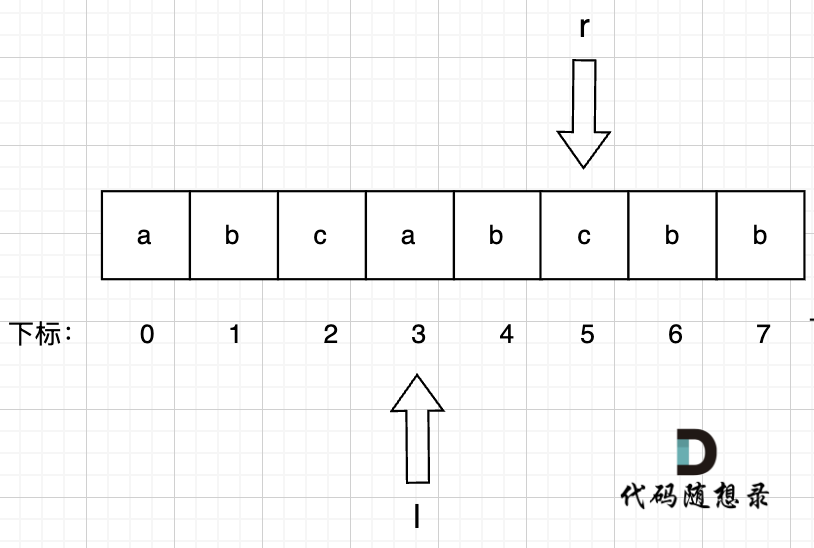
7、右指针 r = 6, 此时右指针指向的位置即s[r] 即 s[6] = b,而b 在 umap里出现过,umap[b] = 4 即 上次b出现的位置是下标4。
此时说明出现重复字符了,那么l就应该移动,减小窗口,左指针l = max(l, umap[s[r]] + 1) = 5 , 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即:
umap[a] = 3
umap[b] = 6
umap[c] = 5
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 3
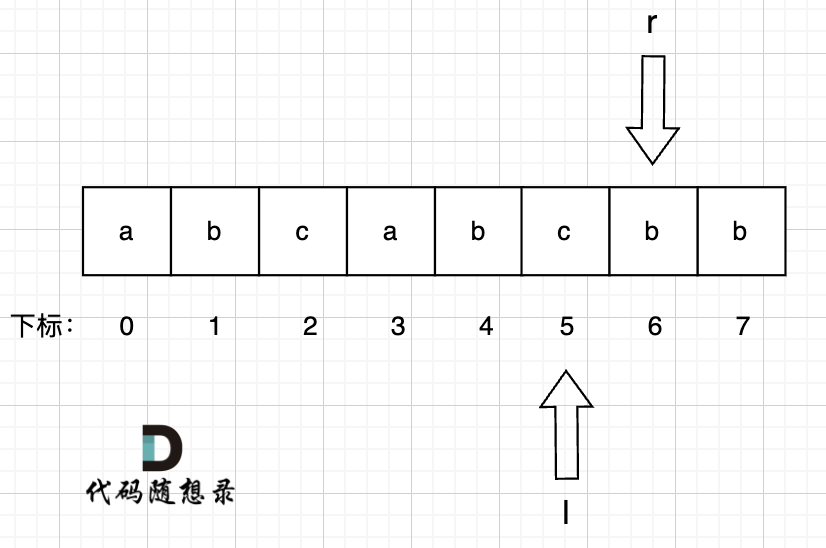
8、右指针 r = 7, 此时右指针指向的位置即s[r] 即 s[7] = b,而b 在 umap里出现过,umap[b] = 6 即 上次b出现的位置是下标6。
此时说明出现重复字符了,那么l就应该移动,减小窗口,左指针l = max(l, umap[s[r]] + 1) = 7 , 用umap记录每个字符最近出现的位置,umap[s[r]] = r ,即:
umap[a] = 3
umap[b] = 7
umap[c] = 5
此时 无重复字符的最长子串 result = max(result, r - l + 1) = 3

至此遍历结束。
时间复杂度为 O(n)
r从左到右只走一遍l也只会单调递增(最多走一遍)- 哈希表查询/更新平均 O(1)
所以整体时间复杂度:O(n)
空间复杂度:O(字符集大小)(最多存每个字符的最新位置)
# 代码实现
# C++
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// 滑动窗口:[l, r]
int l = 0; // 窗口左边界
int result = 0; // 记录最大长度
// 哈希表:记录每个字符最近一次出现的位置(下标)
unordered_map<char, int> umap;
// r 作为窗口右边界,不断向右扩展
for (int r = 0; r < (int)s.size(); r++) {
// 如果 s[r] 曾经出现过,说明窗口可能出现重复
// 需要把 l 移动到“上一次出现位置 + 1”
if (umap.find(s[r]) != umap.end()) {
// 注意:l 只能往右移动,不能往左回退
// 因为可能出现:该字符的上次出现位置在窗口左边界 l 的左侧
l = max(l, umap[s[r]] + 1);
}
// 更新 s[r] 最近一次出现的位置
umap[s[r]] = r;
// 当前窗口长度:r - l + 1
result = max(result, r - l + 1);
}
return result;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# Python3
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
l = 0
res = 0
last = {} # char -> last index
for r, ch in enumerate(s):
if ch in last:
l = max(l, last[ch] + 1) # l 只能右移,不能回退
last[ch] = r
res = max(res, r - l + 1)
return res
2
3
4
5
6
7
8
9
10
11
12
13
# Java
import java.util.HashMap;
class Solution {
public int lengthOfLongestSubstring(String s) {
int l = 0, res = 0;
HashMap<Character, Integer> map = new HashMap<>(); // char -> last index
for (int r = 0; r < s.length(); r++) {
char ch = s.charAt(r);
if (map.containsKey(ch)) {
l = Math.max(l, map.get(ch) + 1); // l 只能右移,不能回退
}
map.put(ch, r);
res = Math.max(res, r - l + 1);
}
return res;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# Go
func lengthOfLongestSubstring(s string) int {
last := make(map[byte]int) // char -> last index
l, res := 0, 0
for r := 0; r < len(s); r++ {
ch := s[r]
if idx, ok := last[ch]; ok {
if idx+1 > l { // l 只能右移,不能回退
l = idx + 1
}
}
last[ch] = r
if r-l+1 > res {
res = r - l + 1
}
}
return res
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# JS
var lengthOfLongestSubstring = function(s) {
let l = 0, res = 0;
const last = new Map(); // char -> last index
for (let r = 0; r < s.length; r++) {
const ch = s[r];
if (last.has(ch)) {
l = Math.max(l, last.get(ch) + 1); // l 只能右移,不能回退
}
last.set(ch, r);
res = Math.max(res, r - l + 1);
}
return res;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 与代码随想录的联系
本题与209.长度最小的子数组 (opens new window) 类似。
两道题本质上都是「连续区间 + 约束条件」
先对比一下两道题的本质描述:
| 题目 | 连续区间 | 约束条件 | 目标 |
|---|---|---|---|
| 209. 长度最小的子数组 | 连续子数组 | 区间和 ≥ target | 长度最小 |
| 3. 无重复字符的最长子串 | 连续子串 | 区间内字符不重复 | 长度最大 |
可以看出:
两道题都是在一个连续窗口中,维护某种“合法性条件”,并在此基础上求窗口长度的最优值。
双指针角色,即l / r 的职责
在随想录的 209 中:
r:不断向右扩展窗口,让区间和变大l:当区间和满足条件后,尝试收缩窗口,让长度更短
在本题中:
r:不断向右扩展窗口,引入新字符l:当窗口出现重复字符时,收缩窗口,避免重复
区别只是“什么时候收缩”。
评论
验证登录状态...